
Что такое двоичный код и как его использовать?
Кодирование числовой информации
Для работы с числовой информацией мы пользуемся системой счисления, содержащей десять цифр: 0 1 2 3 4 5 6 7 8 9. Эта система называется десятичной.
Кроме цифр, в десятичной системе большое значение имеют разряды. Подсчитывая количество чего-нибудь и дойдя до самой большой из доступных нам цифр (до 9), мы вводим второй разряд и дальше каждое последующее число формируем из двух цифр. Дойдя до 99, мы вынуждены вводить третий разряд. В пределах трех разрядов мы можем досчитать уже до 999 и т.д.
Таким образом, используя всего десять цифр и вводя дополнительные разряды, мы можем записывать и проводить математические операции с любыми, даже самыми большими числами.
Компьютер ведет подсчет аналогичным образом, но имеет в своем распоряжении всего две цифры - логический ноль (отсутствие у бита какого-то свойства) и логическая единица (наличие у бита этого свойства).
Система счисления, использующая только две цифры, называется двоичной.
При подсчете в двоичной системе добавлять каждый следующий разряд приходится гораздо чаще, чем в десятичной.
Вот таблица первых десяти чисел в каждой из этих систем счисления:
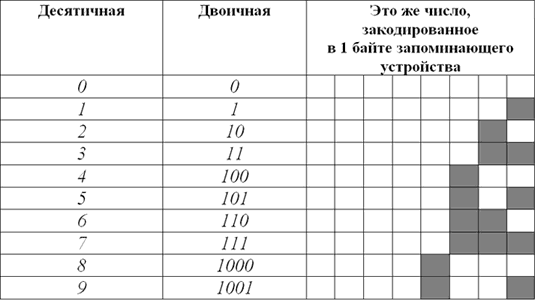
Как видите, в десятичной системе счисления для отображения любой из первых десяти цифр достаточно 1 разряда. В двоичной системе для тех же целей потребуется уже 4 разряда.
Соответственно, для кодирования этой же информации в виде двоичного кода нужен носитель емкостью как минимум 4 бита (0,5 байта).
Человеческий мозг, привыкший к десятичной системе счисления, плохо воспринимает систему двоичную. Хотя обе они построены на одинаковых принципах и отличаются лишь количеством используемых цифр. В двоичной системе точно так же можно осуществлять любые арифметические операции с любыми числами. Главный ее минус - необходимость иметь дело с большим количеством разрядов.
Так, самое большое десятичное число, которое можно отобразить в 8 разрядах двоичной системы - 255, в 16 разрядах – 65535, в 24 разрядах – 16777215.
Компьютер, кодируя числа в двоичный код, основывается на двоичной системе счисления. Но, в зависимости от особенностей чисел, может использовать разные алгоритмы:
Разные алгоритмы:
• Небольшие целые числа без знака
Для сохранения каждого такого числа на запоминающем устройстве, как правило, выделяется 1 байт (8 битов). Запись осуществляется в полной аналогии с двоичной системой счисления.
Целые десятичные числа без знака, сохраненные на носителе в двоичном коде, будут выглядеть примерно так: 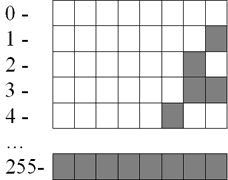
• Большие целые числа и числа со знаком
Для записи каждого такого числа на запоминающем устройстве, как правило, отводится 2-байтний блок (16 битов).
Старший бит блока (тот, что крайний слева) отводится под запись знака числа и в кодировании самого числа не участвует. Если число со знаком "плюс", этот бит остается пустым, если со знаком "минус" – в него записывается логическая единица. Число же кодируется в оставшихся 15 битах.
Например, алгоритм кодирования числа +2676 будет следующим:
- Перевести число 2676 из десятичной системы счисления в двоичную. В итоге получится 101001110100;
Записать полученное двоичное число в первые 15 бит 16-битного блока (начиная с правого края). Последний, 16-й бит, должен остаться пустым, поскольку кодируемое число имеет знак +.
- В итоге +2676 в двоичном коде на запоминающем устройстве будет выглядеть так:

- Примечательно, что в двоичном коде присвоение числу отрицательного значения предусматривает не только изменение старшего бита. Осуществляется также инвертирование всех остальных его битов.
Чтобы было понятно, рассмотрим алгоритм кодирования числа -2676:
Перевести число 2676 из десятичной системы счисления в двоичную. Получим все тоже двоичное число 101001110100;
Записать полученное двоичное число в первые 15 бит 16-битного блока. Затем инвертировать, то есть, изменить на противоположное, значение каждого из 15 битов;
Записать в 16-й бит логическую единицу, поскольку кодируемое число имеет отрицательное значение.
В итоге -2676 на запоминающем устройстве в двоичном коде будет иметь следующий вид:
Двоичное кодирование текстовой информации
Существует несколько общепринятых стандартов кодирования текста в двоичном коде.
Одним из наиболее "старых" (разработан еще в 1960-х гг.) является стандарт ASCII (от англ. American Standard Code for Information Interchange). Это 7-битныйстандарткодирования. То есть, используя его, компьютер записывает каждую букву или знак в одну 7-битную ячейку запоминающего устройства.
Как известно, ячейка из 7 битов может принимать 128 различных состояний. Соответственно, в стандарте ASCII каждому из этих 128 состояний соответствует какая-то буква, знак препинания или специальный символ.
Дальнейшее развитие компьютерной техники показало, что 7-битный стандарт кодирования является слишком "тесным". В 128 состояниях, принимаемых 7-битной ячейкой, невозможно закодировать буквы всех существующих в мире письменностей.
Поэтому разработчики программного обеспечения начали создавать собственные 8-битные стандарты кодировки текста. За счет дополнительного бита диапазон кодирования в них был расширен до 256 символов. Чтобы не было путаницы, первые 128 символов в таких кодировках, как правило, соответствуют стандарту ASCII. Оставшиеся 128 - реализуют региональные языковые особенности.
Восьмибитными кодировками, распространенными в нашей стране, являются KOI8, UTF8, Windows-1251 и некоторые другие.
Разработаны также и универсальные стандарты кодирования текста (Unicode), включающие буквы большинства существующих языков. В них для записи одного символа может использоваться до 16 битов и даже больше.
Существование большого количества кодировок текста является причиной многих проблем. Вы, наверное, уже встречались с ситуацией, когда в некоторых программах на экране вместо букв отображаются непонятные "кракозябры". Это потому, что компьютер иногда "ошибается" и неверно определяет кодировку, в которой этот текст хранится в его памяти.
В перспективе, вероятно, будет принят единый стандарт кодирования текста, полностью учитывающий разнообразие существующих письменностей, на который постепенно перейдут все компьютеры, независимо от локации и используемого программного обеспечения. Но произойдет это, судя по всему, не скоро.